Microsoft expects most of our pages to be placed in c:\inetpub\wwwroot but it provides you an option to map any folder you can find on the server. The methods illustrated here are only works with Windows 2003 (it does not work with Windows XP.
Assuming that you started a new Windows 2003 server, first thing is to copy the codes from old server. Next right click on the IIS as follows:

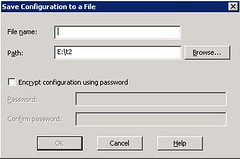
This will generate a XML file containing all the information needed to generate the website.
Edit the xml file and then find the section showing IIsWebVirtualDir as shown below and then duplicate it. Replace the mapping with the ons you need:
In the case above, the virtual directory is engr, so you should be able access it via http://localhost/engr/... The physical folder in the above exmaple is e:\engr.
<IIsWebVirtualDir Location ="/LM/W3SVC/1/ROOT/engr"
AccessFlags="AccessRead | AccessScript"
AppFriendlyName=""
AppIsolated="2"
AppRoot="/LM/W3SVC/1/ROOT/engr"
DirBrowseFlags="DirBrowseShowDate | DirBrowseShowTime | DirBrowseShowSize | DirBrowseShowExtension | DirBrowseShowLongDate | EnableDefaultDoc"
Path="E:\engr"
>
<Custom
Name="Win32Error"
ID="1099"
Value="0"
Type="DWORD"
UserType="IIS_MD_UT_SERVER"
Attributes="INHERIT"
/>
</IIsWebVirtualDir>
You can then edit and map the folder accordingly. Assuming you have configured the IIS to use Framework 1.1, then you will see the following (which defines the default .Net framework when you configure an application):
<IIsWebVirtualDir Location ="/LM/W3SVC/1/ROOT"Virtual folders that needs to use a framework other then the default will need to specify more as in:
AccessFlags="AccessRead | AccessScript"
AppFriendlyName=""
AppIsolated="2"
AppPoolId="DefaultAppPool"
AppRoot="/LM/W3SVC/1/ROOT"
AspEnableParentPaths="TRUE"
AuthFlags="AuthAnonymous | AuthNTLM"
DefaultDoc="Default.htm,Default.asp,iisstart.asp,Default.aspx,index.html"
HttpCustomHeaders="MicrosoftOfficeWebServer: 5.0_Pub
X-Powered-By: ASP.NET"
MimeMap=".chw,application/octet-stream
.lic,application/octet-stream"
Path="E:\webfiles\wwwroot"
ScriptMaps=".asa,C:\WINDOWS\system32\inetsrv\asp.dll,5,GET,HEAD,POST,TRACE
.asax,C:\WINDOWS\Microsoft.NET\Framework\v1.1.4322\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.ascx,C:\WINDOWS\Microsoft.NET\Framework\v1.1.4322\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.ashx,C:\WINDOWS\Microsoft.NET\Framework\v1.1.4322\aspnet_isapi.dll,1,GET,HEAD,POST,DEBUG
.asmx,C:\WINDOWS\Microsoft.NET\Framework\v1.1.4322\aspnet_isapi.dll,1,GET,HEAD,POST,DEBUG
.asp,C:\WINDOWS\system32\inetsrv\asp.dll,5,GET,HEAD,POST,TRACE
.aspx,C:\WINDOWS\Microsoft.NET\Framework\v1.1.4322\aspnet_isapi.dll,1,GET,HEAD,POST,DEBUG
.axd,C:\WINDOWS\Microsoft.NET\Framework\v1.1.4322\aspnet_isapi.dll,1,GET,HEAD,POST,DEBUG
.cdx,C:\WINDOWS\system32\inetsrv\asp.dll,5,GET,HEAD,POST,TRACE
.cer,C:\WINDOWS\system32\inetsrv\asp.dll,5,GET,HEAD,POST,TRACE
.config,C:\WINDOWS\Microsoft.NET\Framework\v1.1.4322\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.cs,C:\WINDOWS\Microsoft.NET\Framework\v1.1.4322\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.csproj,C:\WINDOWS\Microsoft.NET\Framework\v1.1.4322\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.idc,C:\WINDOWS\system32\inetsrv\httpodbc.dll,5,GET,POST
.licx,C:\WINDOWS\Microsoft.NET\Framework\v1.1.4322\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.rem,C:\WINDOWS\Microsoft.NET\Framework\v1.1.4322\aspnet_isapi.dll,1,GET,HEAD,POST,DEBUG
.resources,C:\WINDOWS\Microsoft.NET\Framework\v1.1.4322\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.resx,C:\WINDOWS\Microsoft.NET\Framework\v1.1.4322\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.shtm,C:\WINDOWS\system32\inetsrv\ssinc.dll,5,GET,POST
.shtml,C:\WINDOWS\system32\inetsrv\ssinc.dll,5,GET,POST
.soap,C:\WINDOWS\Microsoft.NET\Framework\v1.1.4322\aspnet_isapi.dll,1,GET,HEAD,POST,DEBUG
.stm,C:\WINDOWS\system32\inetsrv\ssinc.dll,5,GET,POST
.vb,C:\WINDOWS\Microsoft.NET\Framework\v1.1.4322\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.vbproj,C:\WINDOWS\Microsoft.NET\Framework\v1.1.4322\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.vsdisco,C:\WINDOWS\Microsoft.NET\Framework\v1.1.4322\aspnet_isapi.dll,1,GET,HEAD,POST,DEBUG
.webinfo,C:\WINDOWS\Microsoft.NET\Framework\v1.1.4322\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG"
UNCPassword="49634462500000000600000040000000822fdfd482b3000000000000420032004300390042003700420034004600330034004400300038004200320031003100300041003500350039003100460037005d00000000000000"
>
Once you have modified and finalized your file, you can then import it in by right clicking on the IIS and then select new and then create Web Site (from file).
<IIsWebVirtualDir Location ="/LM/W3SVC/1/ROOT/Test2"
AccessFlags="AccessRead | AccessScript"
AppFriendlyName=""
AppIsolated="2"
AppRoot="/LM/W3SVC/1/ROOT/TEST2"
DirBrowseFlags="DirBrowseShowDate | DirBrowseShowTime | DirBrowseShowSize | DirBrowseShowExtension | DirBrowseShowLongDate | EnableDefaultDoc"
Path="E:\testWEb\Test2"
ScriptMaps=".asa,C:\WINDOWS\system32\inetsrv\asp.dll,5,GET,HEAD,POST,TRACE
.asax,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.ascx,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.ashx,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,1,GET,HEAD,POST,DEBUG
.asmx,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,1,GET,HEAD,POST,DEBUG
.asp,C:\WINDOWS\system32\inetsrv\asp.dll,5,GET,HEAD,POST,TRACE
.aspx,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,1,GET,HEAD,POST,DEBUG
.axd,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,1,GET,HEAD,POST,DEBUG
.cdx,C:\WINDOWS\system32\inetsrv\asp.dll,5,GET,HEAD,POST,TRACE
.cer,C:\WINDOWS\system32\inetsrv\asp.dll,5,GET,HEAD,POST,TRACE
.config,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.cs,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.csproj,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.idc,C:\WINDOWS\system32\inetsrv\httpodbc.dll,5,GET,POST
.licx,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.rem,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,1,GET,HEAD,POST,DEBUG
.resources,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.resx,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.shtm,C:\WINDOWS\system32\inetsrv\ssinc.dll,5,GET,POST
.shtml,C:\WINDOWS\system32\inetsrv\ssinc.dll,5,GET,POST
.soap,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,1,GET,HEAD,POST,DEBUG
.stm,C:\WINDOWS\system32\inetsrv\ssinc.dll,5,GET,POST
.vb,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.vbproj,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.vsdisco,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,1,GET,HEAD,POST,DEBUG
.webinfo,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.master,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.skin,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.compiled,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.browser,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.mdb,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.jsl,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.vjsproj,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.sitemap,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.msgx,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,1,GET,HEAD,POST,DEBUG
.ad,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.dd,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.ldd,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.sd,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.cd,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.adprototype,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.lddprototype,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.sdm,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.sdmDocument,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.ldb,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.svc,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,1,GET,HEAD,POST,DEBUG
.mdf,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.ldf,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.java,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.exclude,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG
.refresh,c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll,5,GET,HEAD,POST,DEBUG"
>
</IIsWebVirtualDir>
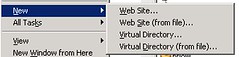
This trick can also be done on the folder level just right clicking on a specific folder get the smaller file. You can then edit the smaller file and add other folders. This is much faster then manually creating individual virtual folders. Once complete then you can use the above to create New Virtual Directory (from file).