I am used to certain type of tools for my programming such as Visual Studio, Netbeans, Context etc. However, it is sometimes quite cumbersome to carry the desktop, notebook every where. With the new breed of portable storage devices like thumb drive and Free Agent, it is possible to carry your programming environment with you.
Ceedo comes with Free Agent. However, the type of applications you can install on it is limited - for example, it is not possible to install Visual Studio on it. A much better option is to use MojoPac. Of course certain software like Antivirus, or softwares that tie directly to the hardware still cannot be installed but it is still a much better option than Ceedo (comes with FreeAgent) or U3 (comes with selected ThumbDrives). Problem with MojoPac, is that it only works with Windows XP. Now that Microsoft is going to stop selling XP, this may not be an option anymore.
Other options like VMWare is more troublesome, you are required to purchase additional Windows License to operate.
However, it raises a problem, what happens if you lose or somebody steals your portable hard disk? The solution is to encrypt the data. One is to use the encryption that comes with Free Agent but it is all or nothing. There are alternatives. Two such alternatives are
The benefit is using either one of the above, is you create a file that contains your virtual volume. That makes it easy for you to specify the size of the volume and to back it up - just copy the file. FreeOTFE also comes with a PDA version, so you can create a virtual secured volume on your PDA to store your accounts/password.
Both software uses very high encryption. Check it out.
Sunday, April 27, 2008
Saturday, April 26, 2008
Woes of a Programmer
Recently, we completed a Windows Application and started running it. This is application was written using Framework 3.5. Strange thing is it runs on several machines but not on two of them - we tried on 8 machines total. Of this 5 of them were identical in every way - Windows, patches etc. Whenever, we run this, it will crash - but only the portion that enables multi threading.
This reminds me of a similar problem I had several years back when I tried using Harvard Graphics on a Acer desktop where the graphics was really bad but not on other machines.
Another incident I experienced more than 15 years ago when we were using MS DOS. I wrote a Clipper program for my office. It copied into two identical machines. Again, it ran on one but not on the other.
I guess I was lucky to encounter all these. We can't blame the programming or the programmer. I wonder whether there are some minor bugs in the processor. Hmmm! This is probably the worst thing that can happen to a programmer. You write your program and tested everything but it does not work on the machine it was meant for.
This reminds me of a similar problem I had several years back when I tried using Harvard Graphics on a Acer desktop where the graphics was really bad but not on other machines.
Another incident I experienced more than 15 years ago when we were using MS DOS. I wrote a Clipper program for my office. It copied into two identical machines. Again, it ran on one but not on the other.
I guess I was lucky to encounter all these. We can't blame the programming or the programmer. I wonder whether there are some minor bugs in the processor. Hmmm! This is probably the worst thing that can happen to a programmer. You write your program and tested everything but it does not work on the machine it was meant for.
Tracing in ASP.Net
Tracing in ASP.Net
Tracing can be enabled either at the page level or for the whole application.
Page level
To activate tracing for a specific page, just add trace=enabled in the page directive as in:
<%@ Page Language="VB" AutoEventWireup="false" CodeFile="Maint.aspx.vb" Inherits="Maint" Trace="True" %>
When enabled at the page level, the trace information will be appended at the bottom of the page.
Application level
The switch to activate it at the application level is in the web.config. The directive is as follows:
<trace enabled="true" requestLimit="10" pageOutput="false" traceMode="SortByTime" localOnly="false"/>
The above tag is within the system.web tag as in:
<system.web>
<trace enabled="true" requestLimit="10" pageOutput="false" traceMode="SortByTime" localOnly="false"/>
</system.web>
With the application level tag, you have additional flexibility:
pageOutput - true will produce the output to the bottom of each page within the application. false will not.
In addition, another output is available - trace.axd page will be available once the trace is enabled at the application level. A sample of trace.axd is shown here:
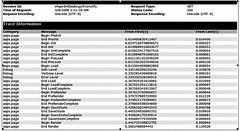
TraceSwitch
TraceSwitch can be used to control the level of tracing to be used in the application. There is two steps to this process:
1. Add an entry in the web.config.
2. Create an object to represent the switch.
The web.config entry looks like this:
<system.diagnostics>
<switches>
<add name="debugSwitch" value="4"/>
<!--
Value options are:
Off 0
Error 1
Warning 2
Info 3
Verbose 4
-->
</switches>
</system.diagnostics>
The above entry must be between the <configuration> and </configuration>. The comment is not necessary but is there to remind me what the values mean.
This is how you access the setting:
Dim dSwitch As New TraceSwitch("debugSwitch", "For TraceDebugging")
With this you have properties to identify the trace level:
.TraceError
.TraceWarning
.TraceInfo
.TraceVerbose
Note that the tracelevel is a hierarchy, which means the higher level will include all messages provided for the lower level. So the value will be <=. E.g. TraceInfo will include messages for TraceInfo, TraceWarning and TraceError.
To help reduce the amount of code, I created a helper subroutine to output the trace messages:
Sub traceMsg(ByVal pLevel As TraceLevel, ByVal pMsg As String)
If dSwitch.Level >= pLevel Then
Trace.Write("Debug", pMsg)
End If
End Sub
Trace.Write is used to output the message to the trace listener - in this case the page trace.axd. Note that the tracelevel is in a hierarchy. It means TraceWarning will show messages for TraceWarning and TraceError - TraceInfo will include TraceWarning and TraceError.
To facilitate coding in multiple applications, you can place this in a common library as a module or a share subroutine and compile it into a library (.dll) and then refer to the library in your subsequent projects.
The following is a sample on how to use the tracing.
Web.config
<?xml version="1.0"?>
<configuration>
<system.web>
<trace enabled="true" requestLimit="10" pageOutput="false" traceMode="SortByTime" localOnly="false"/>
<system.diagnostics>
<switches>
<add name="debugSwitch" value="4"/>
<!--
Value options are:
Off 0
Error 1
Warning 2
Info 3
Verbose 4
-->
</switches>
</system.diagnostics>
</configuration>
Again the key section here is the system.diagnostics and trace.
Tracing can be enabled either at the page level or for the whole application.
Page level
To activate tracing for a specific page, just add trace=enabled in the page directive as in:
<%@ Page Language="VB" AutoEventWireup="false" CodeFile="Maint.aspx.vb" Inherits="Maint" Trace="True" %>
When enabled at the page level, the trace information will be appended at the bottom of the page.
Application level
The switch to activate it at the application level is in the web.config. The directive is as follows:
<trace enabled="true" requestLimit="10" pageOutput="false" traceMode="SortByTime" localOnly="false"/>
The above tag is within the system.web tag as in:
<system.web>
<trace enabled="true" requestLimit="10" pageOutput="false" traceMode="SortByTime" localOnly="false"/>
</system.web>
With the application level tag, you have additional flexibility:
pageOutput - true will produce the output to the bottom of each page within the application. false will not.
In addition, another output is available - trace.axd page will be available once the trace is enabled at the application level. A sample of trace.axd is shown here:
TraceSwitch
TraceSwitch can be used to control the level of tracing to be used in the application. There is two steps to this process:
1. Add an entry in the web.config.
2. Create an object to represent the switch.
The web.config entry looks like this:
<system.diagnostics>
<switches>
<add name="debugSwitch" value="4"/>
<!--
Value options are:
Off 0
Error 1
Warning 2
Info 3
Verbose 4
-->
</switches>
</system.diagnostics>
The above entry must be between the <configuration> and </configuration>. The comment is not necessary but is there to remind me what the values mean.
This is how you access the setting:
Dim dSwitch As New TraceSwitch("debugSwitch", "For TraceDebugging")
With this you have properties to identify the trace level:
.TraceError
.TraceWarning
.TraceInfo
.TraceVerbose
Note that the tracelevel is a hierarchy, which means the higher level will include all messages provided for the lower level. So the value will be <=. E.g. TraceInfo will include messages for TraceInfo, TraceWarning and TraceError.
To help reduce the amount of code, I created a helper subroutine to output the trace messages:
Sub traceMsg(ByVal pLevel As TraceLevel, ByVal pMsg As String)
If dSwitch.Level >= pLevel Then
Trace.Write("Debug", pMsg)
End If
End Sub
Trace.Write is used to output the message to the trace listener - in this case the page trace.axd. Note that the tracelevel is in a hierarchy. It means TraceWarning will show messages for TraceWarning and TraceError - TraceInfo will include TraceWarning and TraceError.
To facilitate coding in multiple applications, you can place this in a common library as a module or a share subroutine and compile it into a library (.dll) and then refer to the library in your subsequent projects.
The following is a sample on how to use the tracing.
Web.config
<?xml version="1.0"?>
<configuration>
<system.web>
<trace enabled="true" requestLimit="10" pageOutput="false" traceMode="SortByTime" localOnly="false"/>
<system.diagnostics>
<switches>
<add name="debugSwitch" value="4"/>
<!--
Value options are:
Off 0
Error 1
Warning 2
Info 3
Verbose 4
-->
</switches>
</system.diagnostics>
</configuration>
Again the key section here is the system.diagnostics and trace.
Friday, April 25, 2008
Writing .Net application without Visual Studio
Even though it is much easier to write .Net application using Visual Studio but it is still possible to write applications using just a notepad. If you have Windows XP, Framework 1.1 comes pre-installed. There is currently two main Frameworks available 1.1 and 2.0. Framework 3.0 and Framework 3.5 are just Framework 2.0 with additional add-ons.
If you have Framework 1.1 installed, the folder will look like this:
C:\WINDOWS\Microsoft.NET\Framework\v1.1.4322
While if you have Framework 2.0 with 3.x installed, you will see
C:\WINDOWS\Microsoft.NET\Framework\v2.0 and then see folder below it.
To compile a program, you need you just need to specify the proper compiler to compile it. Suppose you wrote a program called it HelloWorld.vb, you compile it using the the following command (then it will generate the application HelloWorld.exe):
C:\WINDOWS\Microsoft.NET\Framework\v1.1.4322\vbc HelloWorld.vb
If your program refers to other libraries then you add /r: followed by the list of assemblies it refers to. For example, /r:System.data.dll,System.Web.xml.
For Asp.net applications, you will need to compile it .dll files, so add /t:library. You can also use /o:HelloNewWorld.exe to change the output filename. To compile csc intead of vbc to compile CSharp programs.
If you have Framework 1.1 installed, the folder will look like this:
C:\WINDOWS\Microsoft.NET\Framework\v1.1.4322
While if you have Framework 2.0 with 3.x installed, you will see
C:\WINDOWS\Microsoft.NET\Framework\v2.0 and then see folder below it.
To compile a program, you need you just need to specify the proper compiler to compile it. Suppose you wrote a program called it HelloWorld.vb, you compile it using the the following command (then it will generate the application HelloWorld.exe):
C:\WINDOWS\Microsoft.NET\Framework\v1.1.4322\vbc HelloWorld.vb
If your program refers to other libraries then you add /r: followed by the list of assemblies it refers to. For example, /r:System.data.dll,System.Web.xml.
For Asp.net applications, you will need to compile it .dll files, so add /t:library. You can also use /o:HelloNewWorld.exe to change the output filename. To compile csc intead of vbc to compile CSharp programs.
Wednesday, April 23, 2008
User Controls - ASP and Windows Application
User Controls is a wonderful way to reduce repetitive code. Take for example if you have an application that requires multiple approvers. What do you need for each approver section?
Typically, you will need:
As for the approve and reject button, the user control can then raiseEvent to the parent page to process the event.
To declare an event in the user control, we need to declare the event and then raise the event when the button is clicked. E.g.
Another potential use is a lucky draw display panel, where you may want to display multiple info such as:
So in the UserControl, we group multiple controls together. We then expose these controls through property so that we can set the values. In some cases, you can add logic such as
Typically, you will need:
- Approver Name
- Approver ID
- Approve Button
- Reject Button
- Reason for Rejecting
- Status (when in display mode)
As for the approve and reject button, the user control can then raiseEvent to the parent page to process the event.
To declare an event in the user control, we need to declare the event and then raise the event when the button is clicked. E.g.
Public Event Approve
Private Sub appSubmit_Click(ByVal sender As Object, ByVal e As System.EventArgs) Handles appSubmit.Click
RaiseEvent Approve()
End Sub
Another potential use is a lucky draw display panel, where you may want to display multiple info such as:
- Employee ID
- Employee Name
- Dept
So in the UserControl, we group multiple controls together. We then expose these controls through property so that we can set the values. In some cases, you can add logic such as
- in the case of approval, do not allow the reject to be clicked unless the reject reason is filled.
- hide the textbox for login and password and only display the label displaying the username after the person has already logged in. Also add the login logic within the user control so that we do not have to place logic in multiple pages or applications. (to do that we need to compile the code behind as a separate assembly).
Tuesday, April 22, 2008
Changes in Visual Studio
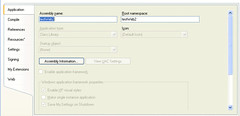
In Visual Studio 2008, one of the changes you see is that the AssemblyInfo.vb (or if you use C#, AssemblyInfo.cs) has been moved to a folder called "My Project". They also provide a interface screen under properties to enter the assembly information.
See the property screen below, there is a button for Assembly Information.
Another change, this was done in Framework 2.0 was to move the database connection strings to a new section called connectionStrings. To access this, we need to import System.configuration.dll and use System.Configuration.ConfigurationManager.ConnectionStrings instead of System.Configuration.ConfigurationSettings.AppSettings (in fact, Microsoft also recommended that we use System.Configuration.ConfigurationManager.AppSettings instead). This new section is created to allow you to encrypt the connection strings for better security - there is a step by step process to do that in the MSDN documentation.
See the property screen below, there is a button for Assembly Information.
Another change, this was done in Framework 2.0 was to move the database connection strings to a new section called connectionStrings. To access this, we need to import System.configuration.dll and use System.Configuration.ConfigurationManager.ConnectionStrings instead of System.Configuration.ConfigurationSettings.AppSettings (in fact, Microsoft also recommended that we use System.Configuration.ConfigurationManager.AppSettings instead). This new section is created to allow you to encrypt the connection strings for better security - there is a step by step process to do that in the MSDN documentation.
Monday, April 21, 2008
Saving the Windows Form to image file programmatically
There is an article found here which shows how to programmatically save the Windows Form directly to an image file. The original code is as follows:
However, I had to place an offset in order to get the image to capture correctly.
My revised code is as follows:
To use the code:
Const SRCCOPY As Integer = &HCC0020
Public Declare Function BitBlt Lib "gdi32" ( _
ByVal hDestDC As IntPtr, _
ByVal x As Integer, _
ByVal y As Integer, _
ByVal nWidth As Integer, _
ByVal nHeight As Integer, _
ByVal hSrcDC As IntPtr, _
ByVal xSrc As Integer, _
ByVal ySrc As Integer, _
ByVal dwRop As Integer _
) As Integer
'================================================= ==================
Public Function CaptureControl(ByVal c As Control) As Bitmap
Dim bmp As Bitmap
Dim gDest, gSource As Graphics
Dim hdcSource, hdcDest As IntPtr
bmp = New Bitmap(c.Width, c.Height)
gSource = c.CreateGraphics
Try
gDest = Graphics.FromImage(bmp)
Try
hdcSource = gSource.GetHdc
Try
hdcDest = gDest.GetHdc
Try
BitBlt( _
hdcDest, 0, 0, _
c.Width, c.Height, _
hdcSource, 0, 0, SRCCOPY _
)
Finally
gDest.ReleaseHdc(hdcDest)
End Try
Finally
gSource.ReleaseHdc(hdcSource)
End Try
Finally
gDest.Dispose()
End Try
Finally
gSource.Dispose()
End Try
Return bmp
End Function
However, I had to place an offset in order to get the image to capture correctly.
My revised code is as follows:
Const SRCCOPY As Integer = &HCC0020
Public Declare Function BitBlt Lib "gdi32" ( _
ByVal hDestDC As IntPtr, _
ByVal x As Integer, _
ByVal y As Integer, _
ByVal nWidth As Integer, _
ByVal nHeight As Integer, _
ByVal hSrcDC As IntPtr, _
ByVal xSrc As Integer, _
ByVal ySrc As Integer, _
ByVal dwRop As Integer _
) As Integer
'================================================= ==================
Public Function CaptureControl(ByVal c As Control) As Bitmap
Dim bmp As Bitmap
Dim gDest, gSource As Graphics
Dim hdcSource, hdcDest As IntPtr
bmp = New Bitmap(c.Width, c.Height)
gSource = c.CreateGraphics
Try
gDest = Graphics.FromImage(bmp)
Try
hdcSource = gSource.GetHdc
Try
hdcDest = gDest.GetHdc
Try
BitBlt( _
hdcDest, 0, 0, _
c.Width, c.Height, _
hdcSource, -3, -27, SRCCOPY _
)
Finally
gDest.ReleaseHdc(hdcDest)
End Try
Finally
gSource.ReleaseHdc(hdcSource)
End Try
Finally
gDest.Dispose()
End Try
Finally
gSource.Dispose()
End Try
Return bmp
End Function
To use the code:
Private Sub btnSave_Click(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles btnSave.Click
Dim x As Bitmap
Me.Activate()
x = CaptureControl(Me)
x.Save("c:\t2.bmp", Imaging.ImageFormat.Bmp)
End Sub
Writing Java stored procedure in Oracle
A good article which provides a step by step process on how to write a Oracle Stored procedure in Java is found here. Java provides some capabilities not found in PL/SQL.
Quote from the article:
Beginning with version 8i, the Oracle database includes a fully functional Java Virtual Machine, Oracle JVM. Out of this close relationship between Oracle and Java emerges an important technology for Oracle developers: Java stored procedures. With Java stored procedures, developers have the ability to harness the power of Java when building database applications. This article provides an overview of this increasingly popular technology. Its intended audience is Java developers new to Oracle, and Oracle PL/SQL developers with a basic understanding of Java. After highlighting the benefits of Java stored procedures, I will demonstrate how to create and use them in your applications.
Benefits of Java Stored Procedures
There are a number of scenarios where it makes sense to use Java stored procedures. Given Java's popularity today, it is certainly possible that members of a development team are more proficient in Java than PL/SQL. Java stored procedures give Java programmers the ability to code in their preferred language. For experienced PL/SQL developers, using Java allows you to take advantage of the Java language to extend the functionality of database applications. Also, Java makes it possible to write database-neutral code. Better yet, it allows you to reuse existing code and dramatically increase productivity.
As you'll see, PL/SQL and Java can coexist quite nicely in the same application so there is no need to pick one or the other. PL/SQL is an excellent procedural language, highly optimized to work with an Oracle database. Java applications that execute in the Oracle database are also highly scalable. In addition, Java executed by the Oracle JVM benefits from efficient garbage collection and the server's thread management capabilities.
Java Stored Procedures, Step by Step
In a nutshell, Java stored procedures are Java classes, stored as Oracle schema objects, made accessible to Oracle SQL and PL/SQL through call specifications. Call specifications, as we will see, are simply PL/SQL declarations that 'wrap' methods of Java stored in the database. There are four necessary steps when developing a Java stored procedure. We will consider each of these steps now.
#1. Writing the Java Class
The beauty of this first step is that it really has little to do with the Oracle database. You simply develop your Java classes using your favorite IDE, such as Oracle's JDeveloper. Java methods must be public and they must be static if they are to be used as stored procedures.
You can write, compile, and even unit test your Java code before moving it into the Oracle database. In fact, for all but trivial applications, this is the preferred method because it will allow you to take advantage of your IDE's features, such as debugging and code generation. If you would prefer to compile your Java classes with Oracle's JVM, the loadjava utility, discussed later, can do this for you.
The following listing displays a simple Java class called EmpManager. For now, it contains a single method to insert an emp record into the database.
#2. Loading Classes
Our Java class is to become a full-fledged schema object, so it needs to be moved into the database. Oracle provides a command-line utility called loadjava to accomplish this task. The loadjava utility essentially provides an interface for SQL CREATE JAVA statements, which also may be used to migrate Java-related files to the database.
Because we've yet to compile EmpManager.java, we'll ask loadjava to do this as part of the loading process. This is achieved by specifying the -resolve attribute on the utility.
$ loadjava -u scott/tiger -v -resolve EmpManager.java
In addition to the -resolve attribute, the -v instructs the utility to include verbose feedback, and the -u specifies the database user and password. Because we asked loadjava to compile the source file, both the source and class files become members of the SCOTT schema.
We can verify the status of the compilation and load with a simple query against USER_OBJECTS. If done correctly, the status is 'VALID'.
SELECT object_name, object_type, status
FROM user_objects WHERE object_type LIKE 'JAVA%';
object_name object_type status
EmpManager JAVA CLASS VALID
EmpManager JAVA SOURCE VALID
Conversely, if compilation fails, errors can be examined through the USER_ERRORS view.
If you choose to compile with an IDE, simply load the resulting class file. Then, the source can reside in version control on the file system. The loadjava utility accepts files with the extensions .sqlj (a sqlj source file), .properties, .ser, .jar, and .zip. In the case of .jar and .zip files, Oracle automatically extracts and stores each member as individual schema objects.
Before we move on, there's one more critical component to the load process that merits discussion: the Oracle JVM resolver. Typically, a JVM uses a classpath to locate Java classes that your program depends upon to run correctly. When storing Java in the database, a resolver accomplishes this.
You can simply think of a resolver as Oracle's version of classpath. Oracle stores core Java classes in the PUBLIC schema. PUBLIC, as well as your own schema, is automatically included in a default resolver. However, if you need to reference a class from another schema, you must provide your own 'resolver spec'. This is done by adding the -resolver attribute. As an example, loadjava -u scott/tiger@test -resolve -resolver "((* SCOTT) (* PUBLIC) (* ADMIN))" specifies that the SCOTT schema, as well as PUBLIC and ADMIN, should be searched when resolving class dependencies.
#3. Publishing Classes
The third step in this process is to publish the Java class. Any class that will be directly called from SQL or PL/SQL must be published. A Java class is published by creating and compiling a call specification for it. The call specification, often referred to as a call spec or even a PL/SQL wrapper, maps a Java method's parameters and return type to Oracle SQL types. Here's the call specification for the addEmp method:
CREATE OR REPLACE PROCEDURE add_emp (emp_id NUMBER,emp_f_name VARCHAR2,
emp_l_name VARCHAR2, emp_salary NUMBER, dept_id NUMBER)
AS LANGUAGE JAVA
NAME 'EmpManager.addEmp(int, java.lang.String, java.lang.String,
float, int)';
/
The add_emp procedure provides an SQL interface to the Java EmpManager.addEmp method. The Java method must be fully specified, including package name if relevant. Also, when developing a call specification, Java objects such as String must be fully qualified.
As a rule of thumb, Java methods with no return value are wrapped as procedures and those with return values become functions. Consider a second Java method in EmpManager that obtains a count of employees for a given department:
//Get the total number of employees for a given department.
public static int getEmpCountByDept(int dept_id) {
Connection conn =
DriverManager.getConnection("jdbc:default:connection:");
String sql = "SELECT COUNT(1) FROM emp WHERE dept_id = ?";
int cnt = 0;
//Code here to add ResultSet value to cnt, trap SQLException, etc.
return cnt;
}
Its call specification specifies that it returns a NUMBER.
CREATE OR REPLACE FUNCTION get_emp_count_by_dept (dept_id NUMBER)
RETURN NUMBER AS LANGUAGE JAVA
NAME 'EmpManager.getEmpCountByDept(int) return int';
/
By default, as with standard PL/SQL procedures, these program units execute with INVOKER rights. In other words, they execute with the privileges of the current user. By adding the keywords AUTHID DEFINER, you allow others to execute with the privileges of the creator.
Once executed, call specifications join the other files in the database as members of the SCOTT schema.
#4. Calling the Procedures
We have developed, loaded, and published our Java classes. The final step is to execute them. By default, Java output is written to trace files. The DBMS_JAVA package, an Oracle-supplied package with utilities for managing server-side Java, has a method for redirecting output to SQL*Plus.
SQL> SET SERVEROUTPUT ON
SQL> CALL dbms_java.set_output(2000);
Now, Java output will displayed upon execution.
SQL> EXECUTE add_emp(1,'Joe', 'Smith',40000.00,1);
Creating new employee...
PL/SQL procedure successfully completed.
As you can see, from the caller's perspective, there is no discernable difference between calls made to Java stored procedures and calls to a PL/SQL procedure or function.
VARIABLE x NUMBER;
CALL get_emp_count_by_dept(1) INTO :x;
Getting Number of Employees for Dept...
Call completed.
PRINT x
X
----------
1
The SQLException class has the getErrorCode() and getErrorMessage() methods to help report errors. Any uncaught exception in a Java Stored Procedure results in an 'ORA-29532 Java call terminated by uncaught Java exception' for the caller. How you choose to handle errors will vary by application. The addEmp method simply catches and displays the error. We receive an error message when we attempt to add an emp record with an invalid dept_id.
SQL> execute add_emp(2,'Tom', 'Jackson', 45000.00,2);
Creating new employee...
ERROR! Adding Employee : ORA-02291: integrity constraint
(OPS$AK4353.FK_DEPT_ID) violated -
parent key not found
Because there is a need to call Java from PL/SQL, it is reasonable to assume that we will also need a way to call PL/SQL from Java code. This is very easy to achieve by using a CallableStatement object in our Java methods.
CallableStatement cstmt = conn.prepareCall("{my_plsql_proc}");
Thus, it is possible to create a seamless environment of PL/SQL procedures calling Java and vice versa.
A Usage Scenario
The better your understanding of Java stored procedures, the easier it will be to decide how they best fit your development practices. A common approach is to use PL/SQL when writing programs primarily concerned with database access. Then, as requirements arise that are more easily satisfied by Java, classes can be developed, followed by the necessary call specifications.
Perhaps, for instance, that a database application needs to interact with operating system files and directories. Oracle provides limited functionality with the UTL_FILE package for accessing system files. However, Java has a far richer set of File IO capabilities, allowing developers to remove files, add directories, and so on. So, why not leverage this power? The user of a command-line PL/SQL program might want to place job parameters in a configuration file. You could write a Java method to read these parameters.
public static String readFile (String usrFile) {
String fileStr = new String();
try {
File file = new File(usrFile);
FileReader fr = new FileReader(file);
LineNumberReader lnr = new LineNumberReader(fr);
...
...
}
catch(Exception e) {
...
}
return fileStr;
}
Then, a PL/SQL package will define call specifications for this and any other FILE IO method you choose to write.
CREATE OR REPLACE PACKAGE my_java_utils IS
FUNCTION read_file (file VARCHAR2) RETURN VARCHAR2;
END my_java_utils;
/
CREATE OR REPLACE PACKAGE BODY my_java_utils IS
FUNCTION read_file (file VARCHAR2) RETURN VARCHAR2
AS LANGUAGE JAVA
NAME 'MyJavaUtils.readFile(java.lang.String) return java.lang.String';
END my_java_utils;
/
A PL/SQL procedure can invoke the Java stored procedure read_file and use a file's data as input. Using this best of both worlds approach, developers can develop a robust database application. It should be noted that in this particular scenario, certain permissions may be required to access the file system. Developers should consult Oracle's Java security documentation for further information.
Quote from the article:
Beginning with version 8i, the Oracle database includes a fully functional Java Virtual Machine, Oracle JVM. Out of this close relationship between Oracle and Java emerges an important technology for Oracle developers: Java stored procedures. With Java stored procedures, developers have the ability to harness the power of Java when building database applications. This article provides an overview of this increasingly popular technology. Its intended audience is Java developers new to Oracle, and Oracle PL/SQL developers with a basic understanding of Java. After highlighting the benefits of Java stored procedures, I will demonstrate how to create and use them in your applications.
Benefits of Java Stored Procedures
There are a number of scenarios where it makes sense to use Java stored procedures. Given Java's popularity today, it is certainly possible that members of a development team are more proficient in Java than PL/SQL. Java stored procedures give Java programmers the ability to code in their preferred language. For experienced PL/SQL developers, using Java allows you to take advantage of the Java language to extend the functionality of database applications. Also, Java makes it possible to write database-neutral code. Better yet, it allows you to reuse existing code and dramatically increase productivity.
As you'll see, PL/SQL and Java can coexist quite nicely in the same application so there is no need to pick one or the other. PL/SQL is an excellent procedural language, highly optimized to work with an Oracle database. Java applications that execute in the Oracle database are also highly scalable. In addition, Java executed by the Oracle JVM benefits from efficient garbage collection and the server's thread management capabilities.
Java Stored Procedures, Step by Step
In a nutshell, Java stored procedures are Java classes, stored as Oracle schema objects, made accessible to Oracle SQL and PL/SQL through call specifications. Call specifications, as we will see, are simply PL/SQL declarations that 'wrap' methods of Java stored in the database. There are four necessary steps when developing a Java stored procedure. We will consider each of these steps now.
#1. Writing the Java Class
The beauty of this first step is that it really has little to do with the Oracle database. You simply develop your Java classes using your favorite IDE, such as Oracle's JDeveloper. Java methods must be public and they must be static if they are to be used as stored procedures.
You can write, compile, and even unit test your Java code before moving it into the Oracle database. In fact, for all but trivial applications, this is the preferred method because it will allow you to take advantage of your IDE's features, such as debugging and code generation. If you would prefer to compile your Java classes with Oracle's JVM, the loadjava utility, discussed later, can do this for you.
The following listing displays a simple Java class called EmpManager. For now, it contains a single method to insert an emp record into the database.
There is nothing out of the ordinary here. Well, almost nothing. In this method, the database connection URL is "jdbc:default:connection:". When writing Java that will execute inside the Oracle database, you can take advantage of a special server-side JDBC driver. This driver uses the user's default connection and provides the fastest access to the database.
import java.sql.*;
import oracle.jdbc.*;
public class EmpManager {
//Add an employee to the database.
public static void addEmp(int emp_id, String emp_f_name,
String emp_l_name,float emp_salary, int dept_id) {
System.out.println("Creating new employee...");
try {
Connection conn =
DriverManager.getConnection("jdbc:default:connection:");
String sql =
"INSERT INTO emp " +
"(emp_id,emp_f_name,emp_l_name,emp_salary,dept_id) " +
"VALUES(?,?,?,?,?)";
PreparedStatement pstmt = conn.prepareStatement(sql);
pstmt.setInt(1,emp_id);
pstmt.setString(2,emp_f_name);
pstmt.setString(3,emp_l_name);
pstmt.setFloat(4,emp_salary);
pstmt.setInt(5,dept_id);
pstmt.executeUpdate();
pstmt.close();
}
catch(SQLException e) {
System.err.println("ERROR! Adding Employee: "
+ e.getMessage());
}
}
}
#2. Loading Classes
Our Java class is to become a full-fledged schema object, so it needs to be moved into the database. Oracle provides a command-line utility called loadjava to accomplish this task. The loadjava utility essentially provides an interface for SQL CREATE JAVA statements, which also may be used to migrate Java-related files to the database.
Because we've yet to compile EmpManager.java, we'll ask loadjava to do this as part of the loading process. This is achieved by specifying the -resolve attribute on the utility.
$ loadjava -u scott/tiger -v -resolve EmpManager.java
In addition to the -resolve attribute, the -v instructs the utility to include verbose feedback, and the -u specifies the database user and password. Because we asked loadjava to compile the source file, both the source and class files become members of the SCOTT schema.
We can verify the status of the compilation and load with a simple query against USER_OBJECTS. If done correctly, the status is 'VALID'.
SELECT object_name, object_type, status
FROM user_objects WHERE object_type LIKE 'JAVA%';
object_name object_type status
EmpManager JAVA CLASS VALID
EmpManager JAVA SOURCE VALID
Conversely, if compilation fails, errors can be examined through the USER_ERRORS view.
If you choose to compile with an IDE, simply load the resulting class file. Then, the source can reside in version control on the file system. The loadjava utility accepts files with the extensions .sqlj (a sqlj source file), .properties, .ser, .jar, and .zip. In the case of .jar and .zip files, Oracle automatically extracts and stores each member as individual schema objects.
Before we move on, there's one more critical component to the load process that merits discussion: the Oracle JVM resolver. Typically, a JVM uses a classpath to locate Java classes that your program depends upon to run correctly. When storing Java in the database, a resolver accomplishes this.
You can simply think of a resolver as Oracle's version of classpath. Oracle stores core Java classes in the PUBLIC schema. PUBLIC, as well as your own schema, is automatically included in a default resolver. However, if you need to reference a class from another schema, you must provide your own 'resolver spec'. This is done by adding the -resolver attribute. As an example, loadjava -u scott/tiger@test -resolve -resolver "((* SCOTT) (* PUBLIC) (* ADMIN))" specifies that the SCOTT schema, as well as PUBLIC and ADMIN, should be searched when resolving class dependencies.
#3. Publishing Classes
The third step in this process is to publish the Java class. Any class that will be directly called from SQL or PL/SQL must be published. A Java class is published by creating and compiling a call specification for it. The call specification, often referred to as a call spec or even a PL/SQL wrapper, maps a Java method's parameters and return type to Oracle SQL types. Here's the call specification for the addEmp method:
CREATE OR REPLACE PROCEDURE add_emp (emp_id NUMBER,emp_f_name VARCHAR2,
emp_l_name VARCHAR2, emp_salary NUMBER, dept_id NUMBER)
AS LANGUAGE JAVA
NAME 'EmpManager.addEmp(int, java.lang.String, java.lang.String,
float, int)';
/
The add_emp procedure provides an SQL interface to the Java EmpManager.addEmp method. The Java method must be fully specified, including package name if relevant. Also, when developing a call specification, Java objects such as String must be fully qualified.
As a rule of thumb, Java methods with no return value are wrapped as procedures and those with return values become functions. Consider a second Java method in EmpManager that obtains a count of employees for a given department:
//Get the total number of employees for a given department.
public static int getEmpCountByDept(int dept_id) {
Connection conn =
DriverManager.getConnection("jdbc:default:connection:");
String sql = "SELECT COUNT(1) FROM emp WHERE dept_id = ?";
int cnt = 0;
//Code here to add ResultSet value to cnt, trap SQLException, etc.
return cnt;
}
Its call specification specifies that it returns a NUMBER.
CREATE OR REPLACE FUNCTION get_emp_count_by_dept (dept_id NUMBER)
RETURN NUMBER AS LANGUAGE JAVA
NAME 'EmpManager.getEmpCountByDept(int) return int';
/
By default, as with standard PL/SQL procedures, these program units execute with INVOKER rights. In other words, they execute with the privileges of the current user. By adding the keywords AUTHID DEFINER, you allow others to execute with the privileges of the creator.
Once executed, call specifications join the other files in the database as members of the SCOTT schema.
#4. Calling the Procedures
We have developed, loaded, and published our Java classes. The final step is to execute them. By default, Java output is written to trace files. The DBMS_JAVA package, an Oracle-supplied package with utilities for managing server-side Java, has a method for redirecting output to SQL*Plus.
SQL> SET SERVEROUTPUT ON
SQL> CALL dbms_java.set_output(2000);
Now, Java output will displayed upon execution.
SQL> EXECUTE add_emp(1,'Joe', 'Smith',40000.00,1);
Creating new employee...
PL/SQL procedure successfully completed.
As you can see, from the caller's perspective, there is no discernable difference between calls made to Java stored procedures and calls to a PL/SQL procedure or function.
VARIABLE x NUMBER;
CALL get_emp_count_by_dept(1) INTO :x;
Getting Number of Employees for Dept...
Call completed.
PRINT x
X
----------
1
The SQLException class has the getErrorCode() and getErrorMessage() methods to help report errors. Any uncaught exception in a Java Stored Procedure results in an 'ORA-29532 Java call terminated by uncaught Java exception' for the caller. How you choose to handle errors will vary by application. The addEmp method simply catches and displays the error. We receive an error message when we attempt to add an emp record with an invalid dept_id.
SQL> execute add_emp(2,'Tom', 'Jackson', 45000.00,2);
Creating new employee...
ERROR! Adding Employee : ORA-02291: integrity constraint
(OPS$AK4353.FK_DEPT_ID) violated -
parent key not found
Because there is a need to call Java from PL/SQL, it is reasonable to assume that we will also need a way to call PL/SQL from Java code. This is very easy to achieve by using a CallableStatement object in our Java methods.
CallableStatement cstmt = conn.prepareCall("{my_plsql_proc}");
Thus, it is possible to create a seamless environment of PL/SQL procedures calling Java and vice versa.
A Usage Scenario
The better your understanding of Java stored procedures, the easier it will be to decide how they best fit your development practices. A common approach is to use PL/SQL when writing programs primarily concerned with database access. Then, as requirements arise that are more easily satisfied by Java, classes can be developed, followed by the necessary call specifications.
Perhaps, for instance, that a database application needs to interact with operating system files and directories. Oracle provides limited functionality with the UTL_FILE package for accessing system files. However, Java has a far richer set of File IO capabilities, allowing developers to remove files, add directories, and so on. So, why not leverage this power? The user of a command-line PL/SQL program might want to place job parameters in a configuration file. You could write a Java method to read these parameters.
public static String readFile (String usrFile) {
String fileStr = new String();
try {
File file = new File(usrFile);
FileReader fr = new FileReader(file);
LineNumberReader lnr = new LineNumberReader(fr);
...
...
}
catch(Exception e) {
...
}
return fileStr;
}
Then, a PL/SQL package will define call specifications for this and any other FILE IO method you choose to write.
CREATE OR REPLACE PACKAGE my_java_utils IS
FUNCTION read_file (file VARCHAR2) RETURN VARCHAR2;
END my_java_utils;
/
CREATE OR REPLACE PACKAGE BODY my_java_utils IS
FUNCTION read_file (file VARCHAR2) RETURN VARCHAR2
AS LANGUAGE JAVA
NAME 'MyJavaUtils.readFile(java.lang.String) return java.lang.String';
END my_java_utils;
/
A PL/SQL procedure can invoke the Java stored procedure read_file and use a file's data as input. Using this best of both worlds approach, developers can develop a robust database application. It should be noted that in this particular scenario, certain permissions may be required to access the file system. Developers should consult Oracle's Java security documentation for further information.
Mind Mapping Tool
Recently more and more people are using mind mapping for brainstorming ideas. This can be an invaluable tool for starting up an application development.
For those not familiar with mind map, you can see the description here.
The following is a mind map for an annual dinner system which we recently worked on.
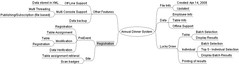
Annual Dinner System
Originally uploaded by strovek
There are a lot of tools available to perform mind mapping. One that is powerful (which is used by a member of my team) is Mind Manager. This application provides a very nice feature to export the mind map to MS PowerPoint, so is excellent for cases where you need to provide a presentation after performing the mind map session.
However, if you just need to perform mind mapping, you can go for freemind. Free mind is a java application, so you need java installed before you can use. It is able to export to html, jpeg etc. It is also able to open Mind Manager files directly. If you are using Mind Manager, you need to use a plug in to import free mind files.
For added bonus, you can use Pocket Freemind, to work on your freemind file straight from your Windows Mobile PDA. However, this requires Compact Framework 2.0 (already built into Windows Mobile 6, you need to install this if you are using earlier version of Windows Mobile).
For those not familiar with mind map, you can see the description here.
The following is a mind map for an annual dinner system which we recently worked on.
Annual Dinner System
Originally uploaded by strovek
There are a lot of tools available to perform mind mapping. One that is powerful (which is used by a member of my team) is Mind Manager. This application provides a very nice feature to export the mind map to MS PowerPoint, so is excellent for cases where you need to provide a presentation after performing the mind map session.
However, if you just need to perform mind mapping, you can go for freemind. Free mind is a java application, so you need java installed before you can use. It is able to export to html, jpeg etc. It is also able to open Mind Manager files directly. If you are using Mind Manager, you need to use a plug in to import free mind files.
For added bonus, you can use Pocket Freemind, to work on your freemind file straight from your Windows Mobile PDA. However, this requires Compact Framework 2.0 (already built into Windows Mobile 6, you need to install this if you are using earlier version of Windows Mobile).
Wednesday, April 16, 2008
Managing Branching in VSS
A good article that provides a step by step approach on how to do branching in Visual SourceSafe can be found here.
The article is as follows:
 The official Microsoft word on branching projects is '132923 Sharing SourceSafe Projects'. It's on the lean side. I've added some more meat that hopefully will help you through the trauma of your first attempt at branching projects.
The official Microsoft word on branching projects is '132923 Sharing SourceSafe Projects'. It's on the lean side. I've added some more meat that hopefully will help you through the trauma of your first attempt at branching projects.

You and i might think it logical to start by specifying the source tree so that the software could check that such a thing actually exists and, gathering confidence as we go, move on to specify where we want to put the new tree. That's being too logical.. The actual sequence of events is ...
1-Destination Project Root | 2-Source Project Name | 3-Destination Project Name
If and when the Status bar shows 'Ready' Click [Close] to exit the 'Share with ..' dialog. And go and have a cold one. You deserve it.
The Small Print
If NOT SELECTED you'll see double document icons in the Client2 tree indicating that file appearances in the Word and Client2 trees are still only backed by one physical file in SourceSafe, so changes to one appear in both.
If SELECTED you'll see single document icons in the client2 tree indicating that each file is now backed by it's own physical file (the Client2 files were copied from the Word files which is why you made sure you have plenty of free disc space to accomodate the growth in the database size).
Pinning
If you want to refine the torture your brain has already endured, and assuming that you elected the 'Branch after Share' checkbox, then you might want to consider pinning.
In this case the files in the Client2 branched project tree have a separate history from now on, and can be modified at will without affecting the corresponding files in the the Word tree.
However it's quite likely that you don't want some, perhaps most, of the files in the branched tree to be changed, and you want to lock those down so they stay the same as the originals.
The SourceSafe term for locking them down.is 'Pinning'.
This is really a separate topic, but if you want to dip a toe in start here
Afterword
The article is as follows:
You and i might think it logical to start by specifying the source tree so that the software could check that such a thing actually exists and, gathering confidence as we go, move on to specify where we want to put the new tree. That's being too logical.. The actual sequence of events is ...
1-Destination Project Root | 2-Source Project Name | 3-Destination Project Name
1. click on the project UNDER WHICH the DESTINATION project tree is to be created. In this case we'll suppose we want to create the replicated tree off the root so select $/
2. Right click on $/ and click again on 'Share' on the menu.
3. On the 'Share with' dialog Select the head of the SOURCE project tree you want to branch. In this case select project Word 1.
You may want to check the [] Branch after Share checkbox, but for now just let's defer that. The dialogs we're trekking through are very un-intuitive. I'll get to the effect of checking that later.
4. Click the [Share] button
5.Now we're in a second 'Share $/Word1' dialog.
The system doesn't know what the name of the DESTINATION project tree is to be at this point. All it knows is that it's going to hang it off of the project you specified in 1. above.
In the 'New Name' field enter the name for the head of the DESTINATION project tree. In this case, since we're creating the DESTINATION project as a peer of $/Word 1 it can't have the same name, so let's call it Client2. However all the child projects will retain their original names.
6. Now IMPORTANT! check the [Recursive] box or all we'll get is $/Client2!
Enter in the comment box
'I have lead a clean life, and I have backed up the database,
and made sure I have at LEAST double the free space the current database takes up,
and I have run analyze in the hope it will clean up the deleted files and any
and all broken links in the tree
and I truly believe that SourceSafe will recurse over the thousands of projects
and files in the tree I want to branch without breaking and leaving a gawdawful mess.
I do. I do. I do.'
Lastly place chicken entrails or rabbits foot to taste on the keyboard and
7. click on [Ok].
If and when the Status bar shows 'Ready' Click [Close] to exit the 'Share with ..' dialog. And go and have a cold one. You deserve it.
The Small Print
- If you think that this dialog sequence is .. awkward .. imho you'd be right.
- If you want to place the destination tree somewhere in the tree where it's not a peer to the source tree then the head source and destination names can be the same as there won't be a conflict.
- Don't specify a destination tree that overlaps with the source tree or you'll get "A project cannot be shared under a descendent" messages indicating that you're trying to do illegal recursion.
- Selecting the 'branch after share' checkbox has this effect:
If NOT SELECTED you'll see double document icons in the Client2 tree indicating that file appearances in the Word and Client2 trees are still only backed by one physical file in SourceSafe, so changes to one appear in both.
If SELECTED you'll see single document icons in the client2 tree indicating that each file is now backed by it's own physical file (the Client2 files were copied from the Word files which is why you made sure you have plenty of free disc space to accomodate the growth in the database size).
Pinning
If you want to refine the torture your brain has already endured, and assuming that you elected the 'Branch after Share' checkbox, then you might want to consider pinning.
In this case the files in the Client2 branched project tree have a separate history from now on, and can be modified at will without affecting the corresponding files in the the Word tree.
However it's quite likely that you don't want some, perhaps most, of the files in the branched tree to be changed, and you want to lock those down so they stay the same as the originals.
The SourceSafe term for locking them down.is 'Pinning'.
This is really a separate topic, but if you want to dip a toe in start here
Afterword
There's a good writup on Branching in Larry Whipple's excellent book 'Essential Sourcesafe'.
You'll find a link to it on the 'SourceSafe Third Party Tools' page.
When you do get to it click on the 'Search inside this book' link under the jacket image. When you get the next page scroll up the page to uncover 'Search [Inside this book]. Finally select the 'on Page 51' link.
I say this not to do Larry out of his royalties but to encourage you to try and buy the book. If you're a professional SourceSafe administrator i'd say it's pretty well ... essential.
Thursday, April 10, 2008
Multi Lingual Windows Application
A very good article on how to perform Localization of Windows application can be found here. I have not tried to see how well it works.
Wednesday, April 9, 2008
Off line scalable computing
For our annual dinner, we need to create a windows application for registering employees as they enter the hall to be used to perform lucky draw. Since there is a large number of employees, we need to be able scale to multiple computers for scanning their badges.
We also want to simplify the requirement for the hardware so we do not want to install databases etc on the computer. We just want to have .Net Framework and our application on the computers. So I thought I will share an approach with you.
We assume that we will have a computers together and then use shared folders.
The following is a snapshot of the demo program:
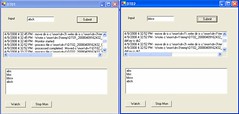
If you key in input into one screen, it will be captured into the second screen. Each screen represents a different computer. In this example I used two folders.
This is the config file for the first computer:
For the sake of demo, I create two listbox. In order to support threadsafe updating of Windows Control I created a delegate (This was discussed in an earlier blog).
Delegate Sub SetTextCallback(ByVal [text] As String)
I have created two subroutine one for each listbox:
ChkLBSize controls the number of rows maintained in each ListBox.
Next we have a global variable to facilitate stopping of the folder monitoring:
Dim StopMon As Boolean = False
We can have also some constants to determine how many rows to maintain in the listbox and how many rows to remove once the threshold is exceeded:
Const maxLen As Integer = 20
Const delNum As Integer = 5
We then have a button to start and a button to stop the folder monitoring:
The monitoring process is as follows:
Notice that the process is broken into three parts - can be combined if you want to. I prefer to do it this way. Go through a infinite loop and exit only when the StopMon is set to True. IThe processDir will then look up all the files, extract out the parts of the filename and pass the processing to the processFile. In processFile, I will read the file and then perform all the necessary process. In this example, it just display the output to the lbMsg2 by call SetText2.
As for the publishing, there is a button to submit the input from the TextBox:
In this case, I use a global variable vEntry. Monitor is used to lock the string object when updating the value. This value is then used to write to the files. The following generates the files:
We also want to simplify the requirement for the hardware so we do not want to install databases etc on the computer. We just want to have .Net Framework and our application on the computers. So I thought I will share an approach with you.
We assume that we will have a computers together and then use shared folders.
The following is a snapshot of the demo program:
If you key in input into one screen, it will be captured into the second screen. Each screen represents a different computer. In this example I used two folders.
This is the config file for the first computer:
This is the config file for the second computer:
<?xml version="1.0" encoding="utf-8" ?>
<configuration>
<appSettings>
<add key="ConName" value="DT01" />
<add key="monDir" value="c:\mon\drv1\" />
<add key="dirCnt" value="2" />
<add key="dir1" value="c:\mon\drv2\" />
<add key="dir2" value="c:\mon\drv3\" />
</appSettings>
</configuration>
<?xml version="1.0" encoding="utf-8" ?>In this case, each time we scan a badge in each computer, it will publish a text file to the folders in for the other computers (number of computers identified by the dirCnt. The application will also monitor any new files published by other computers to it - identified by monDir. ConName is the console name which identifies the computer name and is also used to create distinct file name when publishing.
<configuration>
<appSettings>
<add key="ConName" value="DT02" />
<add key="monDir" value="c:\mon\drv2\" />
<add key="dirCnt" value="2" />
<add key="dir1" value="c:\mon\drv1\" />
<add key="dir2" value="c:\mon\drv3\" />
</appSettings>
</configuration>
For the sake of demo, I create two listbox. In order to support threadsafe updating of Windows Control I created a delegate (This was discussed in an earlier blog).
Delegate Sub SetTextCallback(ByVal [text] As String)
I have created two subroutine one for each listbox:
' Used to allow multiple threads to update the textbox.
Private Sub SetText(ByVal [text] As String)
' InvokeRequired required compares the thread ID of the
' calling thread to the thread ID of the creating thread.
' If these threads are different, it returns true.
If Me.lbMsg.InvokeRequired Then
Dim d As New SetTextCallback(AddressOf SetText)
Me.Invoke(d, New Object() {[text]})
Else
Me.lbMsg.Items.Add([text])
chkLBSize()
End If
End Sub
' Used to allow multiple threads to update the textbox.
Private Sub SetText2(ByVal [text] As String)
' InvokeRequired required compares the thread ID of the
' calling thread to the thread ID of the creating thread.
' If these threads are different, it returns true.
If Me.lbMsg2.InvokeRequired Then
Dim d As New SetTextCallback(AddressOf SetText2)
Me.Invoke(d, New Object() {[text]})
Else
Me.lbMsg2.Items.Add([text])
chkLBSize()
End If
End Sub
' To maintain the entries to lex then maxCnt
Private Sub chkLBSize()
Dim loopCnt, indx As Integer
If lbMsg.Items.Count > maxLen Then
indx = 0
For loopCnt = 1 To delNum
lbMsg.Items.RemoveAt(indx)
If lbMsg.Items.Count <= 0 Then
Exit For
End If
Next
End If
If lbMsg2.Items.Count > maxLen Then
indx = 0
For loopCnt = 1 To delNum
lbMsg2.Items.RemoveAt(indx)
If lbMsg2.Items.Count <= 0 Then
Exit For
End If
Next
End If
End Sub
ChkLBSize controls the number of rows maintained in each ListBox.
Next we have a global variable to facilitate stopping of the folder monitoring:
Dim StopMon As Boolean = False
We can have also some constants to determine how many rows to maintain in the listbox and how many rows to remove once the threshold is exceeded:
Const maxLen As Integer = 20
Const delNum As Integer = 5
We then have a button to start and a button to stop the folder monitoring:
Private Sub btnWatch_Click(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles btnWatch.Click
Dim createThrd As Boolean = True
If IsNothing(monThrd) = False Then
If monThrd.IsAlive Then
createThrd = False
End If
End If
If createThrd Then
Monitor.Enter(StopMon)
StopMon = False
Monitor.Exit(StopMon)
Dim thrd As New Thread(AddressOf monFile)
thrd.Start()
monThrd = thrd
Else
SetText(Now & " - Monitoring already started")
End If
End Sub
Private Sub btnStopWatch_Click(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles btnStopWatch.Click
Monitor.Enter(StopMon)
StopMon = True
Monitor.Exit(StopMon)
End Sub
The monitoring process is as follows:
Private Sub monFile()
Dim monDir As String = AppSettings("monDir")
SetText(String.Format("{0} - Monitor started", Now))
While (True)
If StopMon Then
Exit While
End If
processDir(monDir)
Thread.Sleep(600)
End While
SetText(String.Format("{0} - Monitor Stopped", Now))
End Sub
Sub processDir(ByVal pDir As String)
Dim fName, fName2 As String
Dim fObj As File
If (Directory.Exists(pDir) = False) Then
SetText(String.Format("{0} - {1} directory does not exist", Now, pDir))
Else
For Each fName In Directory.GetFiles(pDir)
fName2 = Path.GetFileName(fName)
SetText(String.Format("{0} - process file {1} - name is {2}", Now, fName, fName2))
processFile(fName, fName2, pDir)
Next
End If
End Sub
Sub processFile(ByVal pFullFname As String, ByVal pFname As String, ByVal monDir As String)
Dim sr As StreamReader = New StreamReader(pFullFname)
Dim rline, tFolder, tFile As String
rline = sr.ReadLine
SetText2(rline)
sr.Close()
tFolder = monDir & "done\"
tFile = tFolder & pFname
File.Move(pFullFname, tFile)
SetText(String.Format("{0} - processed completed. Moved {1} to {2}", Now, pFullFname, tFile))
End Sub
Notice that the process is broken into three parts - can be combined if you want to. I prefer to do it this way. Go through a infinite loop and exit only when the StopMon is set to True. IThe processDir will then look up all the files, extract out the parts of the filename and pass the processing to the processFile. In processFile, I will read the file and then perform all the necessary process. In this example, it just display the output to the lbMsg2 by call SetText2.
As for the publishing, there is a button to submit the input from the TextBox:
Private Sub btnSubmit_Click(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles btnSubmit.Click
' Locks vEntry so that other threads cannot access
Monitor.Enter(vEntry)
vEntry = txtEntry.Text
' Unlock vEntry after use
Monitor.Exit(vEntry)
spawnThrd()
SetText2(txtEntry.Text)
End Sub
In this case, I use a global variable vEntry. Monitor is used to lock the string object when updating the value. This value is then used to write to the files. The following generates the files:
Sub spawnThrd()SpawnThrd will create and start a thread for each of entries. creFile will loop through each of the folders identified by the dirX (as in dir1, dir2 etc) in the config file. The dirCnt facilitates this. The unique file name is achieve using a combination of Console Name (conName in config file), date and time and also a running number. Also to reduce the possibility of read/write contention, the files are written in a temp sub-folder before being moved to the main folder.
Dim thrd As New Thread(AddressOf creFile)
thrd.Start()
End Sub
Sub creFile()
Dim fCnt, vFCnt, loopCnt As Integer
Dim vMsg, fName, fWriteDir, fMoveDir, dirKey As String
Monitor.Enter(vEntry)
vMsg = vEntry
Monitor.Exit(vEntry)
Monitor.Enter(vFileCnt)
vFCnt = vFileCnt
vFileCnt += 1
Monitor.Exit(vFileCnt)
fCnt = AppSettings("dirCnt")
For loopCnt = 1 To fCnt
dirKey = "dir" & loopCnt
SetText("dirKey is " & dirKey)
fMoveDir = AppSettings(dirKey)
fWriteDir = fMoveDir & "temp\"
fName = AppSettings("conName") & "_" & Format(Now, "yyyyMMddHH24mm") & "_" & vFCnt & ".txt"
SetText(String.Format("{0} - move dir is {1} write dir is {2} and filename is {3}", Now, fMoveDir, fWriteDir, fName))
writeFile(fMoveDir, fWriteDir, fName, vEntry)
Next
End Sub
Sub writeFile(ByVal pMoveDir As String, ByVal pWriteDir As String, ByVal pFname As String, ByVal pMsg As String)
Dim fName, tFname As String
fName = pWriteDir & pFname
tFname = pMoveDir & pFname
Dim sw As StreamWriter = New StreamWriter(fName)
sw.Write(pMsg)
sw.Close()
File.Move(fName, tFname)
SetText(String.Format("{0} - Wrote {1} and moved to {2}", Now, fName, tFname))
End Sub
Tuesday, April 8, 2008
Updating a Windows Application Textbox in a multithreading environment
The following is based on the article from MSDN website.
Basically, it says that we need to declare a delegate:
Basically, it says that we need to declare a delegate:
Delegate Sub SetTextCallback([text] As String)Then in the routine that updates the textbox will check if it is in the thread id and will transfer the control to the thread that owns the textbox.Private Sub SetText(ByVal [text] As String)
' InvokeRequired required compares the thread ID of the
' calling thread to the thread ID of the creating thread.
' If these threads are different, it returns true.
If Me.textBox1.InvokeRequired Then
Dim d As New SetTextCallback(AddressOf SetText)
Me.Invoke(d, New Object() {[text]})
Else
Me.textBox1.Text = [text]
End If
End Sub
Monday, April 7, 2008
Lotus NOTES - Inbox missing mail
Sometimes when there is corruption, mails disappear from the inbox. The following are some solutions:
In some cases, just performing an Updall will fix it.
Other cases, we just delete the $Inbox and then reapply the template.
Finally, we need to actually convert it to another template, convert it back and then delete the $Inbox folder and then reapply the latest template.
The command to convert the template will be like follows (execute from the LN Console):
l convert -s mail\mailfile.nsf * inotes6.ntf
In some cases, just performing an Updall will fix it.
Other cases, we just delete the $Inbox and then reapply the template.
Finally, we need to actually convert it to another template, convert it back and then delete the $Inbox folder and then reapply the latest template.
The command to convert the template will be like follows (execute from the LN Console):
l convert -s mail\mailfile.nsf * inotes6.ntf
Sunday, April 6, 2008
Taking a ASP.Net 2.0 application off line
Just saw an in ASP.Net that you can easily take a ASP.Net 2.0 by placing a app_offline.htm file into the root of the application folder. A couple of articles explaining this are shown below:
http://forums.asp.net/t/1242889.aspx
http://weblogs.asp.net/scottgu/archive/2005/10/06/426755.aspx
There are a lot more such articles if you google them.
http://forums.asp.net/t/1242889.aspx
http://weblogs.asp.net/scottgu/archive/2005/10/06/426755.aspx
There are a lot more such articles if you google them.
Saturday, April 5, 2008
Notes appear over your words when you mouseover words on your document
One of my users is using Lotus Quickr to create documents asked me how do they create notes so that when other users move their mouse over the word, they will see notes about the word (i.e. a short note on the description of a training.
The first thing I thought of was to use CSS and there is actually a very nice tutorial available. However, it looks too complicated for a normal user (non programmer). Then I remember another trick I used in another project, basically just add the "Title" to a "a href" just like this (move your mouse over the word this")
The link looks like this
this
Problem with Quickr, is if you have to do this is "html source" mode. It is also important to put the title properties in front of the href. This is because when you switch back to compose mode, Quickr will add in the fully qualified address instead of the relative address. When this happens, the browser may not detect the title property and therefore will not show the note. Also, you need to commit your changes before switching back to compose mode otherwise you will lose your changes.
The first thing I thought of was to use CSS and there is actually a very nice tutorial available. However, it looks too complicated for a normal user (non programmer). Then I remember another trick I used in another project, basically just add the "Title" to a "a href" just like this (move your mouse over the word this")
The link looks like this
this
Problem with Quickr, is if you have to do this is "html source" mode. It is also important to put the title properties in front of the href. This is because when you switch back to compose mode, Quickr will add in the fully qualified address instead of the relative address. When this happens, the browser may not detect the title property and therefore will not show the note. Also, you need to commit your changes before switching back to compose mode otherwise you will lose your changes.
Thursday, April 3, 2008
Multi Lingual Web sites using ASP.Net
In one of our projects, we were given a task to create a website that supports multi languages. Majority of the samples were difficult to test and implement. The best one I found so far is in the video found in the ASP.Net website.
This is what I have derived from the video.

The resulting html tag will be as follows:
<asp:Label ID="lblMessage" runat="server"
Text="<%$ Resources:LocalizedText, Msg1 %>"></asp:Label>
For example if the ClassKey is "LocalizedText", then the resx files will be:
LocalizedText.fr.resx for French
LocalizedText.ms.resx for Malay
LocalizedText.resx for the default.
In the above example the files should all be placed in App_GlobalResources under the application folder (just like there is a bin under the application folder).
As for the resource entry, this is a sample of the resource file entry interface in Visual Studio:

This is a sample of the overridden method:
Protected Overrides Sub InitializeCulture()
Dim lang As String = Request("Language1")
If lang IsNot Nothing Or lang <> "" Then
Thread.CurrentThread.CurrentUICulture = New CultureInfo(lang)
Thread.CurrentThread.CurrentCulture = CultureInfo.CreateSpecificCulture(lang)
End If
End Sub
In the above example, I used the dropdownlist similar to the video:
<asp:DropDownList ID="Language1" runat="server" AutoPostBack="True">
<asp:ListItem>auto</asp:ListItem>
<asp:ListItem Value="en-US">English</asp:ListItem>
<asp:ListItem Value="ms-MY">Malay</asp:ListItem>
<asp:ListItem Value="fr-FR">French</asp:ListItem>
</asp:DropDownList>
However, given the logic, we can also use a url parameter, radio button etc to identify the language.
To deployment, it will be like normal with the additional App_GlobalResources folder to copy.
This was the key thing I was looking for. In majority of the examples I saw, the language is automatically detected based on the browser setting. This will not work if the users are sharing a public computer to access the site.
This is what I have derived from the video.
- This only applies for Framework 2.0 and above (not applicable for Framework 1.1).
- We need to override the InitializeCulture in the page class (or codebehind class).

The resulting html tag will be as follows:
<asp:Label ID="lblMessage" runat="server"
Text="<%$ Resources:LocalizedText, Msg1 %>"></asp:Label>
For example if the ClassKey is "LocalizedText", then the resx files will be:
LocalizedText.fr.resx for French
LocalizedText.ms.resx for Malay
LocalizedText.resx for the default.
In the above example the files should all be placed in App_GlobalResources under the application folder (just like there is a bin under the application folder).
As for the resource entry, this is a sample of the resource file entry interface in Visual Studio:

This is a sample of the overridden method:
Protected Overrides Sub InitializeCulture()
Dim lang As String = Request("Language1")
If lang IsNot Nothing Or lang <> "" Then
Thread.CurrentThread.CurrentUICulture = New CultureInfo(lang)
Thread.CurrentThread.CurrentCulture = CultureInfo.CreateSpecificCulture(lang)
End If
End Sub
In the above example, I used the dropdownlist similar to the video:
<asp:DropDownList ID="Language1" runat="server" AutoPostBack="True">
<asp:ListItem>auto</asp:ListItem>
<asp:ListItem Value="en-US">English</asp:ListItem>
<asp:ListItem Value="ms-MY">Malay</asp:ListItem>
<asp:ListItem Value="fr-FR">French</asp:ListItem>
</asp:DropDownList>
However, given the logic, we can also use a url parameter, radio button etc to identify the language.
To deployment, it will be like normal with the additional App_GlobalResources folder to copy.
This was the key thing I was looking for. In majority of the examples I saw, the language is automatically detected based on the browser setting. This will not work if the users are sharing a public computer to access the site.
Tuesday, April 1, 2008
Oracle Partition
One of the features that are sometimes overlooked in Oracle is partitioning. I found partitioning to be useful to simplify housekeeping of data that can be done based on date range.
I like to think of partition as table within a table. In fact, based on the documentations I read in SQL Server, that is how that is done. Create a table and then a view that refers to them. Personally, I like Oracle's implementation - each is so much easier to manage.
As for housekeeping, from experience deleting few thousand records will take 30 to 40 minutes but dropping the partition takes less than a minute. Some additional benefits of dropping the partition is that the space released by the partition is returned to the workspace and can be reused by any other table using the workspace. For deletion the space freed may not be reusable.
For example, I have a system that we extract high volume of transaction on an hourly basis for processing. This data is no longer needed after processing. In this instance we create a partition by date range:
CREATE TABLE LOTTXNTAB
(
LOTID VARCHAR2(20),
TXNTIME DATE,
EXTDATE DATE,
QTY NUMBER,
STEP VARCHAR2(20)
)
PARTITION BY RANGE(EXTDATE)
( PARTITION lottxntab0 VALUES LESS THAN(to_date('20070101','yyyymmdd')));
In another scenario where we have leave records that we upload for multiple departments but we still want to separate drop based on the date range. Also the data is obtained from separate data file and uploaded daily but we wish to retain only one copy for each week. We can then use the date as the partition key and deptnumber as the sub-partition key.
CREATE TABLE ELEAVETAB
(
EMPNO VARCHAR2(20),
TXNTIME DATE,
WEEKCUTOFF DATE,
LBALANCE NUMBER,
DEPTNO VARCHAR2(20)
)
PARTITION BY RANGE(WEEKCUTOFF)
SUBPARTITION BY LIST(DEPTNO) SUBPARTITION TEMPLATE
(
SUBPARTITION S1 VALUES('PNG')
, SUBPARTITION S2 VALUES('SNG')
)
(
PARTITION ELEAVETAB0 VALUES LESS THAN(to_date('20070101','yyyymmdd')),
PARTITION ELEAVETAB_1 VALUES LESS THAN(TO_DATE('20080201','YYYYMMDD'))
);
This way, I can update the data for each dept and then check to see if I can delete other data for the dept for the week before loading the new data then drop partition for both depts once the retention date has exceeded. Also, when the new partition is created, the subpartitions will also be automatically created.
One thing to note, then when using partition, it is advisable to use local index instead of global index. This is because if we use global index, we need to rebuild the index whenever we drop any partition.
Also when creating partition, you cannot create partition of an smaller range than the one that already exist.
I like to think of partition as table within a table. In fact, based on the documentations I read in SQL Server, that is how that is done. Create a table and then a view that refers to them. Personally, I like Oracle's implementation - each is so much easier to manage.
As for housekeeping, from experience deleting few thousand records will take 30 to 40 minutes but dropping the partition takes less than a minute. Some additional benefits of dropping the partition is that the space released by the partition is returned to the workspace and can be reused by any other table using the workspace. For deletion the space freed may not be reusable.
For example, I have a system that we extract high volume of transaction on an hourly basis for processing. This data is no longer needed after processing. In this instance we create a partition by date range:
CREATE TABLE LOTTXNTAB
(
LOTID VARCHAR2(20),
TXNTIME DATE,
EXTDATE DATE,
QTY NUMBER,
STEP VARCHAR2(20)
)
PARTITION BY RANGE(EXTDATE)
( PARTITION lottxntab0 VALUES LESS THAN(to_date('20070101','yyyymmdd')));
In another scenario where we have leave records that we upload for multiple departments but we still want to separate drop based on the date range. Also the data is obtained from separate data file and uploaded daily but we wish to retain only one copy for each week. We can then use the date as the partition key and deptnumber as the sub-partition key.
CREATE TABLE ELEAVETAB
(
EMPNO VARCHAR2(20),
TXNTIME DATE,
WEEKCUTOFF DATE,
LBALANCE NUMBER,
DEPTNO VARCHAR2(20)
)
PARTITION BY RANGE(WEEKCUTOFF)
SUBPARTITION BY LIST(DEPTNO) SUBPARTITION TEMPLATE
(
SUBPARTITION S1 VALUES('PNG')
, SUBPARTITION S2 VALUES('SNG')
)
(
PARTITION ELEAVETAB0 VALUES LESS THAN(to_date('20070101','yyyymmdd')),
PARTITION ELEAVETAB_1 VALUES LESS THAN(TO_DATE('20080201','YYYYMMDD'))
);
This way, I can update the data for each dept and then check to see if I can delete other data for the dept for the week before loading the new data then drop partition for both depts once the retention date has exceeded. Also, when the new partition is created, the subpartitions will also be automatically created.
One thing to note, then when using partition, it is advisable to use local index instead of global index. This is because if we use global index, we need to rebuild the index whenever we drop any partition.
Also when creating partition, you cannot create partition of an smaller range than the one that already exist.
Subscribe to:
Comments (Atom)